In diesem Artikel möchten wir Ihnen Beispiele zeigen, wie das Testen von IoT-Geräten mittels AI-gestützter Bilderkennung unterstützt werden kann.
Vorstellung des Projekts
Das Testobjekt
In diesem Beispiel wollen wir automatisiert Informationen über den Zustand einer Kaffeemaschine herausfinden. Wir wollen anhand der Anzeige der Maschine automatisiert erfassen, ob der Wassertank in der Maschine eingesetzt wurde und ob sich eaine Tasse unterhalb des Auslaufs befindet. Die Schwierigkeit besteht in diesem Beispiel darin, dass die Maschine keine expliziten Testschnittstellen für beide Testfälle anbietet. Es müssten hierfür Sensoren entwickelt und an der Maschine angebracht werden um diese Informationen automatisiert verarbeiten zu können. Dies ist sehr aufwendig, da dies technische Kenntnisse voraussetzt und die Testmethodik einen hohen Grad der Intrusion aufweist und somit einer erfolgreichen Automatisierung im Weg steht. Daher muss eine bessere Lösung gefunden werden.
Die Teststrategie
Wir wollen mit diesem Beispiel zeigen, dass sich mittels AI-gestützter Bilderkennungssoftware diese Testfälle automatisiert durchführen lassen. Hierfür entwickeln wir mittels des Frameworks Tensorflow ein Tool, welches zum einen aus Bildern des Displays der Kaffeemaschine erkennen kann, ob auf diesem eine Warnung wegen des nicht eingesetzten Wassertanks erscheint und zum anderen aus Bildern einer Frontalaufnahme der Kaffeemaschine erkennen kann, ob eine Tasse auf diesen Bildern zu sehen ist. Der Einsatz einer Bildklassifizierungssoftware ist hier sinnvoll, da wir eine begrenzte Anzahl von fest voneinander abgrenzbaren Zuständen haben.
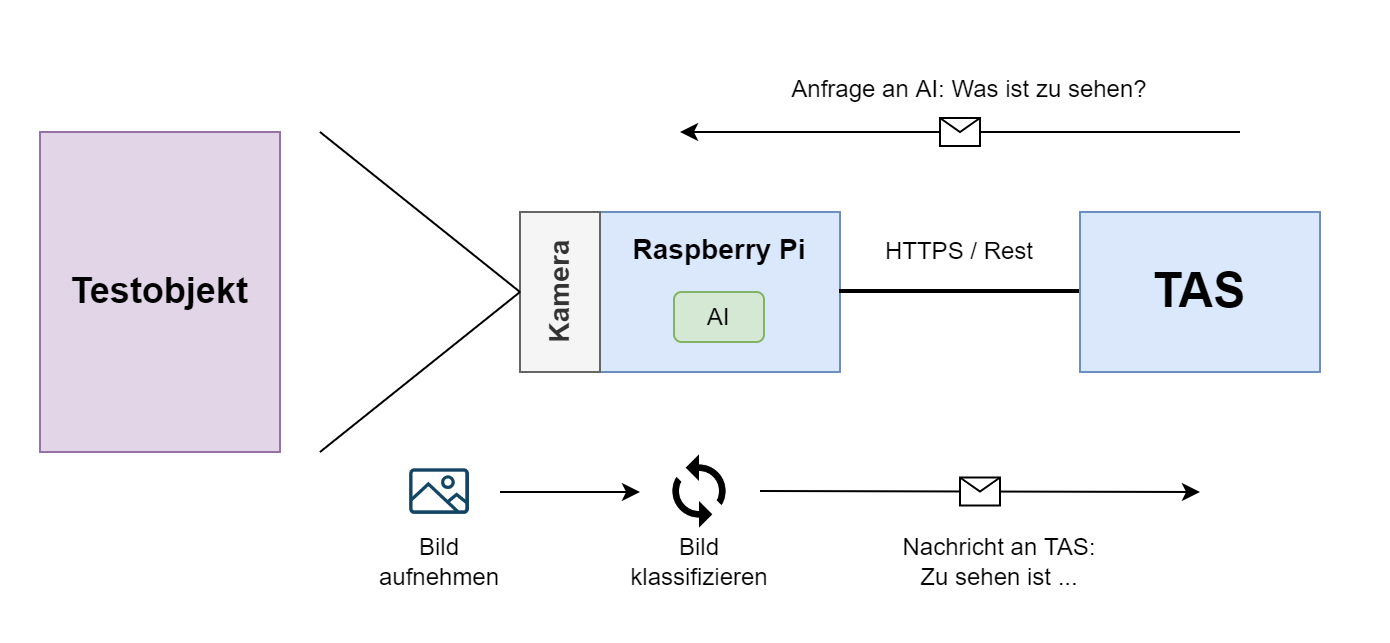
Die Testschnittstelle
Für das automatisierte Testen ist es notwendig, dass die erfassten Daten der Bilderkennung von einer TAS (Test Automation Solution) genutzt werden können. Hierfür sollte es über eine API möglich sein, den Status der Kaffeemaschine abzufragen. Hier empfiehlt es sich eine spezialisierte REST-API zu entwickeln, die über die TAS Daten abfragen oder Daten aktiv durch die Bilderkennungssoftware in eine Datenbank schreiben kann.
Verwendete Technologien
Für die Erstellung des Modells, sowie die Anwendung des Modells auf den Bilddateien, wird die Programmiersprache Python und das Framework Tensorflow verwendet. Die REST-API kann ebenfalls mit Python und einem Framework wie etwa Flask implementiert werden. Es wurden keine kommerziellen Tools von Drittanbietern genutzt.
Erstellung des AI-Modells zur Erkennung der Zustände
Trainingsbilder erstellen
Zum Trainieren des Modells benötigen wir zunächst Bilder, die die Zustände unserer beiden Szenarien zeigen. Für den ersten Testfall benötigen wir zum einen Bilder, die das Display im Normalzustand und zum anderen die entsprechende Fehlermeldung bei fehlendem Wassertank zeigen. Für den zweiten Testfall werden entsprechend Bilder mit und ohne Tasse unter dem Auslauf benötigt.
Hier sehen Sie eine Auswahl von Trainingsbildern für den ersten Testfall. In der oberen Bildreihe sehen Sie das Display im Normalzustand, unten das Display wenn der Wasserbehälter entfernt wurde. Für den ersten Testfall wurden jeweils 450 Trainings- und 150 Testbilder für jeden der beiden Fälle aufgenommen. Die Bilder wurden von einem Smartphone mit dem Serienbildmodus aufgenommen, daher stellte die Erstellung großer Bildmengen kein Problem dar. Bei der Aufnahme der Bilder wurde die Kamera bewegt und geneigt, sodass Bilder aus verschiedenen Blickwinkeln aufgenommen wurden.