

Selenium, Cypress und Playwright brauchen technisches Verständnis und kosten Wartung, sobald sich Selektoren ändern. Genau hier setzen KI-gestützte Testing-Tools an: Self-Healing, Visual-AI und natürliche Sprache versprechen weniger Aufwand und schnellere Test-Erstellung.
Ich habe acht der relevantesten KI-Tools für Software-Testing 2026 angeschaut und gegenübergestellt: Applitools, AskUI, Functionize, Virtuoso, Mabl, TestSprite, Testim und KaneAI. Für jedes Tool findest du den Praxis-Fokus, die Stärke und für welches Team es passt.
Wenn du dich für die Grundlagen von KI im Software-Testing interessierst (ISTQB CT-GenAI, Prompt-Patterns, Halluzinations-Schutz), lies parallel den KI-Pillar-Artikel. Dieser Hub konzentriert sich auf die Tool-Auswahl.
Inhaltsverzeichnis
- Was KI-Tools im Testing leisten
- Schnellvergleich: 8 KI-Tools auf einen Blick
- Applitools
- AskUI
- Functionize
- Virtuoso
- Mabl
- TestSprite
- Testim by Tricentis
- KaneAI by LambdaTest
- Auswahl-Matrix: Welches Tool für welchen Use-Case
- Fallstricke und Anti-Patterns
- Fazit: 2026 ist das Jahr der Hybrid-Strategien
- Häufig gestellte Fragen
Was KI-Tools im Testing leisten
Die acht Tools in diesem Vergleich kombinieren vier KI-Fähigkeiten in unterschiedlichem Mix. Bevor du dich für eines entscheidest, klär für dein Team, welche Fähigkeit am meisten Hebel bringt.
Self-Healing-Selektoren
Ändert sich ein Selektor im DOM, repariert die KI ihn automatisch beim nächsten Lauf. Statt eines roten Tests bekommst du ein Self-Heal-Symbol und einen Diff aus altem und neuem Selektor. Applitools, Functionize, Mabl, Testim und Virtuoso können das. Spart in der Praxis 30 bis 50 Prozent Wartungszeit, ersetzt aber kein Code-Review wenn die UI strukturell umgebaut wird.
Visual-AI
Statt Selektoren vergleicht die KI gerendertes Pixel-für-Pixel mit einer Baseline. Bewertet semantisch, ob ein Unterschied relevant ist (neue Marketing-Banner werden ignoriert, verschobene Buttons gemeldet). Applitools und AskUI sind hier führend, Mabl hat es als Zusatz integriert.
Natürliche Sprache und Codeless-Authoring
Tests werden in Plain English (oder Deutsch) geschrieben: „Logge dich ein, klicke auf Warenkorb, prüfe dass der Gesamtpreis 79,90 Euro beträgt." Die KI übersetzt das in Aktionen. Virtuoso, Functionize und KaneAI gehen diesen Weg konsequent. Senkt die Einstiegshürde für Fachbereich und Manual-Tester, kann aber bei komplexen Flows uneindeutig werden.
AI-generierte Tests aus Code oder Spec
Die KI liest deinen Source-Code, deine OpenAPI-Spec oder dein UI-Screenshot und generiert Tests dazu. TestSprite ist hier der Spezialist (42 auf 93 Prozent Pass-Rate nach einer Iteration laut eigenem Benchmark). Sinnvoll für Unit-Tests als Sicherheitsnetz gegen KI-generierten Code oder API-Test-Erstgeneration.
Schnellvergleich: 8 KI-Tools auf einen Blick
| Tool | Kategorie | USP 2026 | Beste Use-Case | Pricing-Stufe |
|---|---|---|---|---|
| Applitools | Visual-AI | Eyes Universal SDK + Autonomous AI | UI-Regression über viele Browser/Viewports | Enterprise |
| AskUI | Visual + RPA | Heidelberger Vision-Modell, kein DOM nötig | Native Desktop-Apps, Cross-Device | Mid-Market |
| Functionize | NL + Self-Heal | Adaptive Language Processing, Xray-Anbindung | End-to-End mit Test-Daten-Generation | Enterprise |
| Virtuoso | Low-Code NL | Journey-basiert, API-Test-Manager integriert | Business-Tester ohne Code-Hintergrund | Mid-Market |
| Mabl | CI/CD + Auto-Heal | Native GitHub/Azure-Pipelines, Gartner 4.9/5 | High-Velocity-Teams in DevOps-Pipelines | Mid-Market |
| TestSprite | AI-Code-Validation | MCP-native, validiert KI-generierten Code | Dev-Teams mit Copilot/Claude-Workflow | Startup-friendly |
| Testim | Self-Healing + Smart-Locator | Tricentis-Akquisition, Code-Mode für Devs | Hybrid-Teams Codeless + Custom-Code | Enterprise |
| KaneAI | NL Test-Generation | Test-Plan-Agent in Plain English, LT-Grid | Cross-Browser + Multi-Device-Coverage | Mid-Market |
Applitools
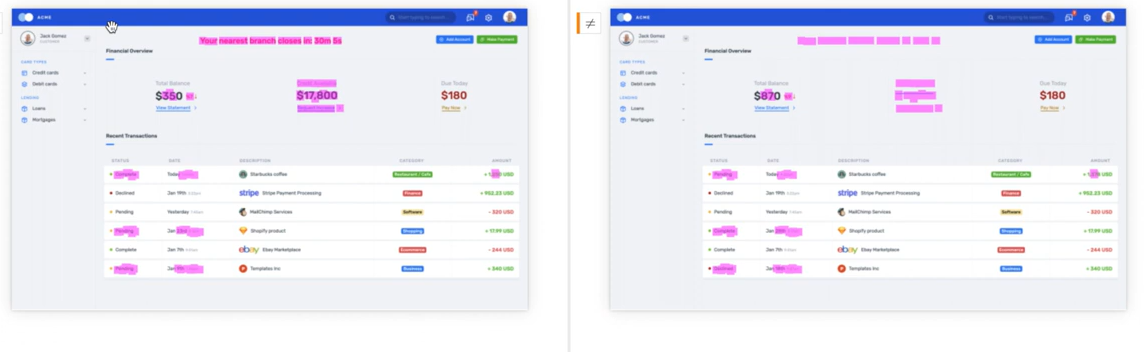
Applitools (gegründet 2013, Boston) ist der Visual-AI-Pionier. Eyes-SDK vergleicht Screenshots vor und nach dem Test gegen eine intelligente Baseline. Unterschiede werden farblich markiert; semantisch unwichtige Differenzen (Animations-Frames, Marketing-Banner) ignoriert die KI automatisch.
Das hauseigene Framework verkürzt Testfälle messbar. Statt 15 Zeilen Selenium- oder Playwright-Code brauchst du oft nur 5 Zeilen mit Applitools-Wrapper:

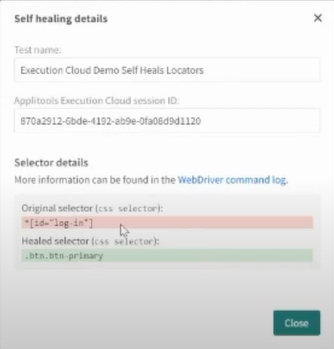
Self-Healing greift, sobald sich Selektoren ändern. Ein Zauberstab-Icon im Test-Report zeigt dir an, dass die KI eingegriffen hat. Beim Klick auf das Icon öffnet sich der Diff zwischen altem und neuem Selektor:
Applitools integriert sich in Playwright, Selenium, Cypress und WebdriverIO und passt damit in bestehende Frameworks. Wenn du Visual-Regression über viele Viewports brauchst und schon ein klassisches E2E-Framework hast, ist Applitools die Standard-Antwort.
AskUI
AskUI ist die deutsche Antwort auf Visual-Testing. Heidelberger Startup, gegründet 2021, mit eigenem Vision-Modell. Der Clou: AskUI braucht keine Selektoren und kein DOM. Es erkennt Buttons, Textfelder und Checkboxen rein über das gerenderte Bild, wie ein menschlicher Tester.
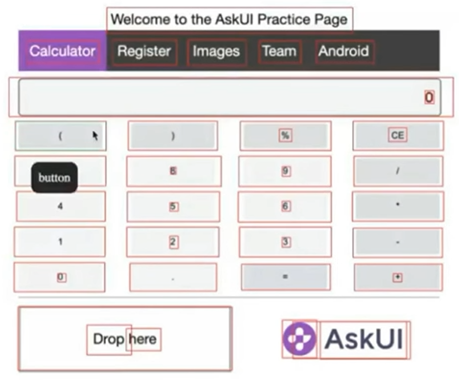
Das macht AskUI stark für Szenarien, die andere Frameworks nicht abdecken: native Desktop-Anwendungen ohne Selenium-Grid, Cross-Device-Tests zwischen Desktop und Mobile, sogar 2-Faktor-Authentifizierung quer durch zwei Geräte.
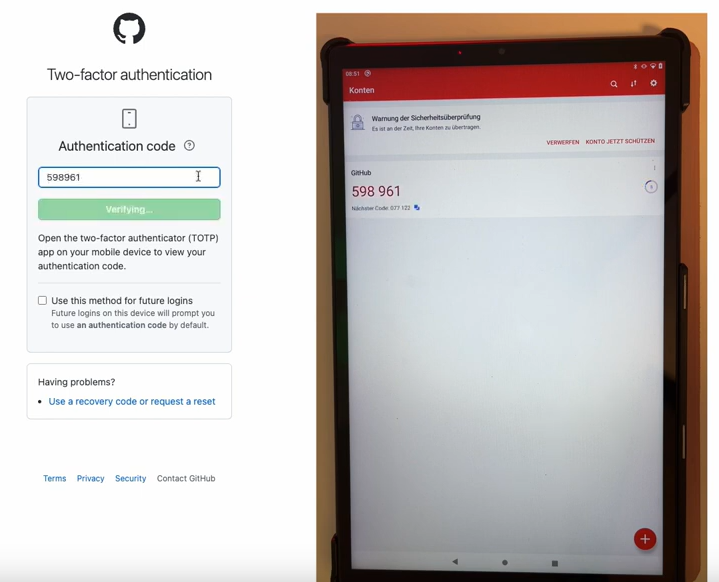
Ein Feature, das sonst kein anderes Tool im Vergleich hat: AskUI bewegt den Mauszeiger sichtbar während der Testläufe. Du siehst den Test wie einen Bildschirm-Recording-Stream ablaufen, was Demos vor Stakeholdern radikal vereinfacht. Stärker noch: AskUI lässt sich auch für Robotic Process Automation (RPA) einsetzen, weil das gleiche Vision-Modell sowohl Tests als auch reale Click-Flows ausführen kann.
Functionize
Functionize (gegründet 2014, San Diego) kombiniert Recorder-basiertes Authoring mit ML-gestützter Adaption. Die Aufnahme läuft im Browser, der Recorder zeigt dir die DOM-Struktur live an, sobald du über ein Element fährst:
Stärker als andere Recorder: Functionize generiert Testdaten on-the-fly. E-Mail-Adressen, Telefonnummern, strukturierte Test-Datensätze in beliebigen Formaten kommen aus der Plattform, ohne dass du eine Faker-Library einbinden musst:
Wer mehr Kontrolle will, schaltet auf Code-Mode um und schreibt Custom-Logik:
Self-Healing markiert Functionize mit einem gelben Balken und „Self-Heal"-Label. Beim Drauf-Klicken siehst du den Diff zwischen altem und neuem Wert:

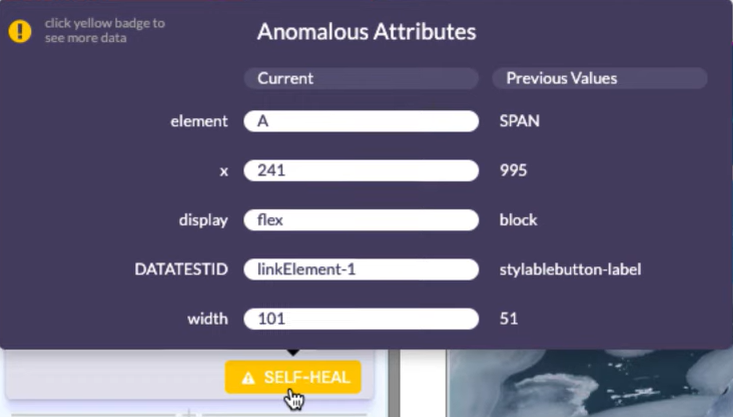
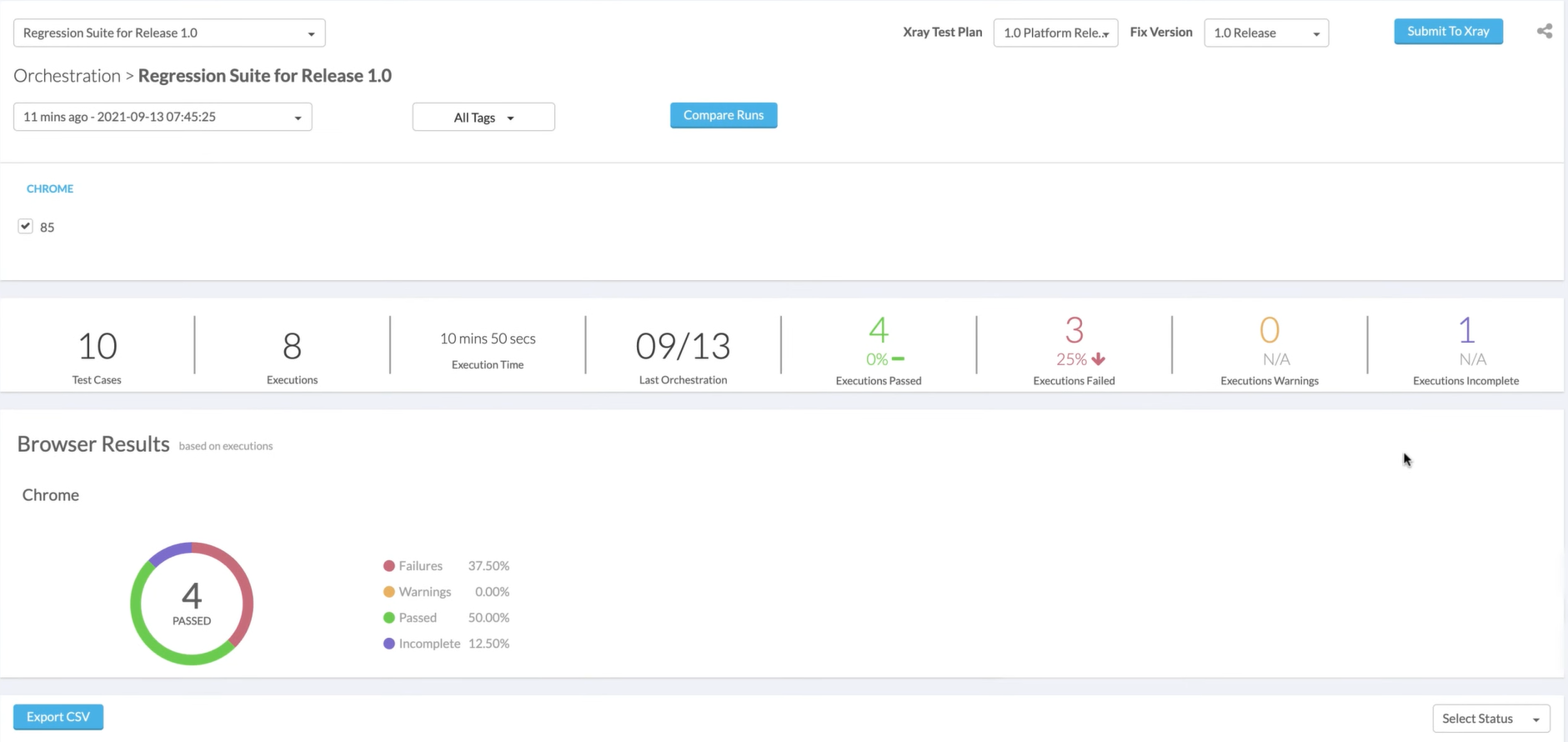
Besonders praktisch für Testmanager: Functionize bringt eine native Xray-Integration mit. Du kannst aus dem Test-Management heraus Functionize-Test-Pläne anstoßen und Reports zurück in Jira/Xray spielen.

Virtuoso
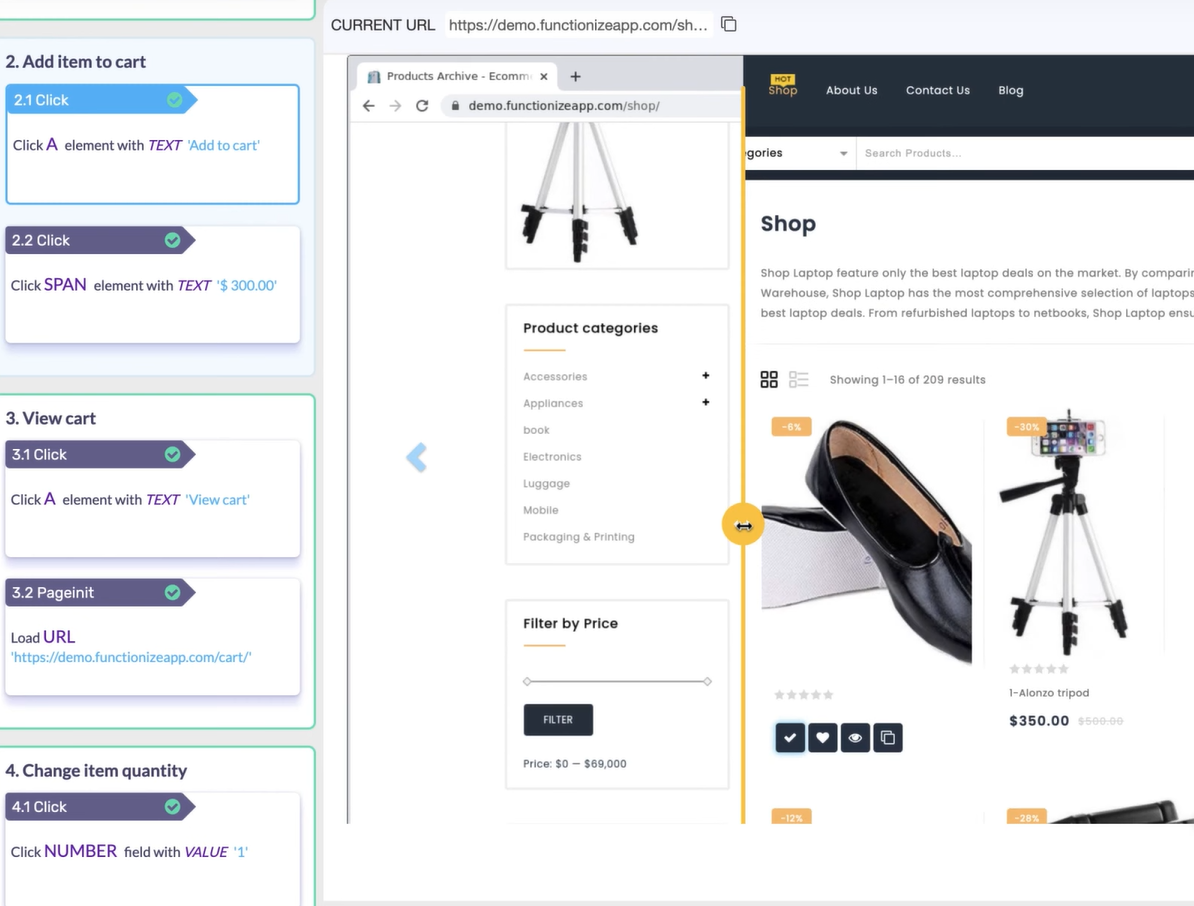
Virtuoso (gegründet 2016, London) ist Low-Code-NL-Authoring zur Perfektion getrieben. Du schreibst Testschritte in natürlicher Sprache. Die KI übersetzt sie in Aktionen:
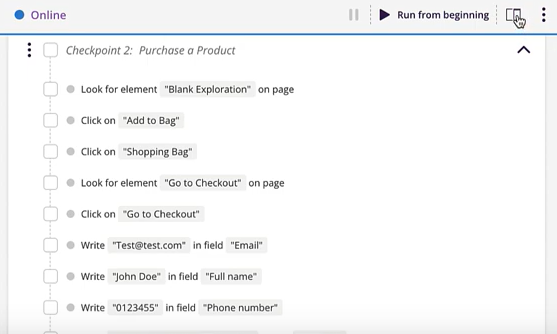
Die Architektur basiert auf wiederverwendbaren Checkpoints und übergeordneten Journeys, die End-to-End-User-Flows abbilden:
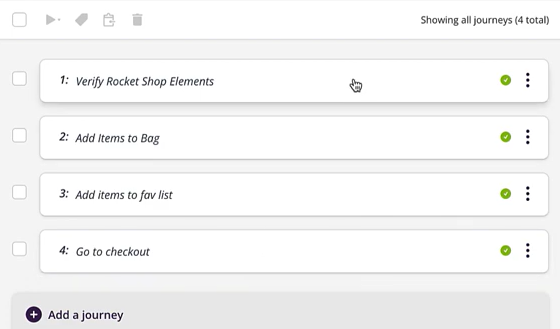
Während der Ausführung öffnet sich ein Seiten-Preview-Fenster mit der gerenderten Anwendung:
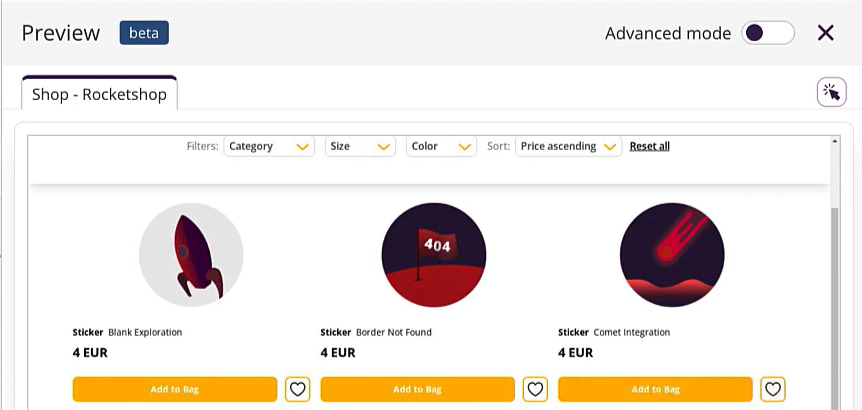
Wer API-Tests parallel braucht: Virtuoso bringt einen eigenen API-Test-Manager mit, sodass du nicht zusätzlich Postman oder Bruno einbinden musst:
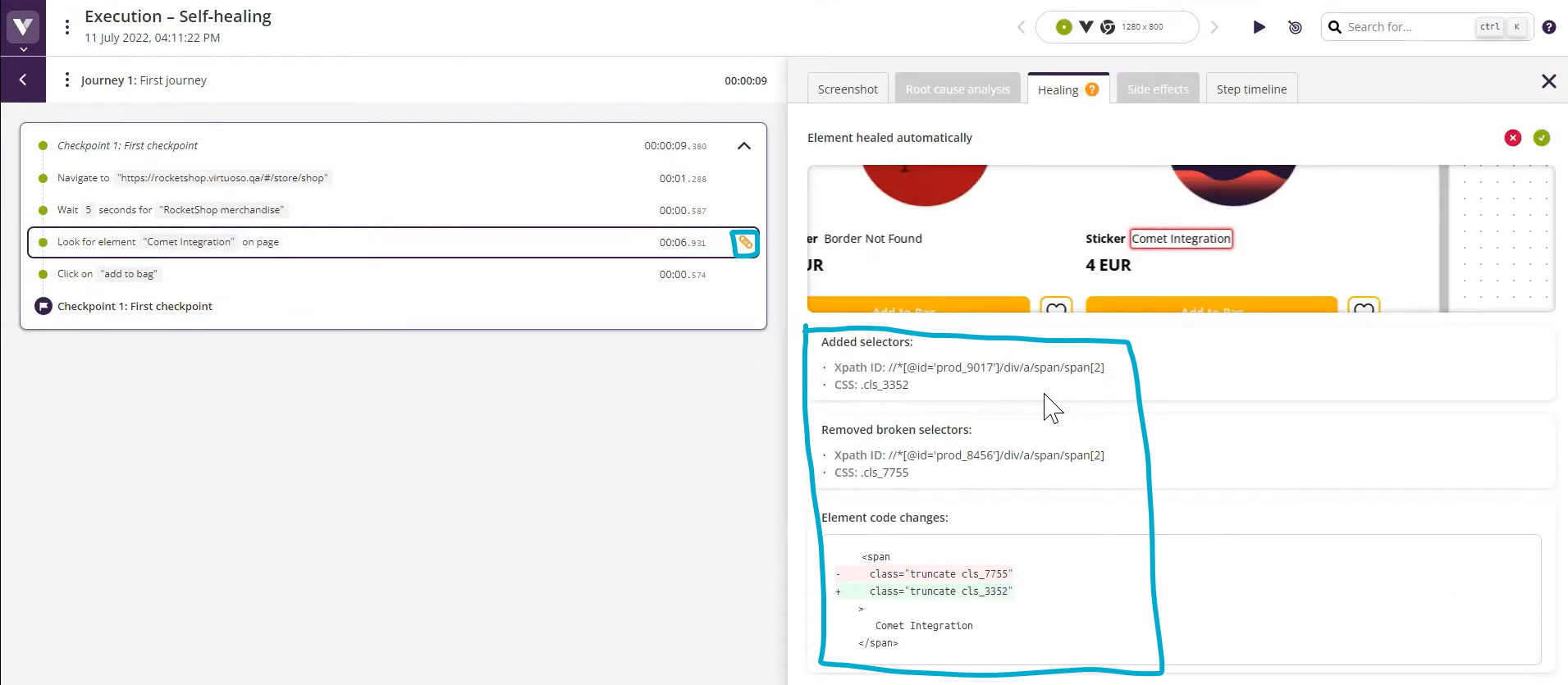
Self-Healing kennzeichnet Virtuoso mit einem Ketten-Icon. Klick rein und du siehst Vergleich von altem zu neuem Selektor:
Mabl
Mabl (gegründet 2017 von Ex-Googlern, Boston) ist konsequent für DevOps-Teams gebaut. Cloud-only, native Anbindung an GitHub Actions, GitLab CI, Azure DevOps und Jenkins. Auf Gartner Peer Insights schneidet Mabl mit 4.9 von 5 Sternen ab, eine der höchsten Bewertungen im Visual-AI-Segment.
Der Praxis-Unterschied zu Applitools: Mabl ist Test-Lifecycle-Plattform, nicht nur Visual-Engine. Du schreibst Tests im Low-Code-Recorder, lässt sie cloud-parallel laufen, bekommst Auto-Healing direkt im Mabl-Workflow und Reports in Slack. Die ML-Modelle adaptieren sich pro Application-Under-Test individuell: was bei deiner Banking-App ein „relevanter UI-Bruch" ist, kann bei deiner Marketing-Site noch ignoriert werden.
Wenn dein Team auf Playwright oder Cypress setzt aber den CI-Wartungsaufwand satthat, ist Mabl die naheliegende Hybrid-Strategie: kritische User-Journeys in Mabl, Component-Tests in Playwright/Cypress.
TestSprite
TestSprite (Launch 2024) verfolgt eine andere Wette als alle anderen Tools in dieser Liste: KI gegen KI. Wenn dein Team mit GitHub Copilot, Cursor oder Claude Code arbeitet, generiert die KI Code, der oft halb-fertig ist. TestSprite läuft im Hintergrund, validiert den generierten Code und liefert strukturierte Fixes zurück an den Coding-Agent.
Laut TestSprite-eigenem Benchmark steigt die Pass-Rate von 42 Prozent (Roh-Output GPT/Claude/DeepSeek) auf 93 Prozent nach einer Iteration mit TestSprite. Die Tool-Integration läuft über MCP (Model Context Protocol), das heißt: dein IDE-Agent ruft TestSprite direkt als MCP-Server auf.
Konsequenz für die Praxis: TestSprite ist kein Ersatz für E2E-Tests, sondern ein Validierungs-Layer für KI-generierten Code. Stärkste Use-Cases sind Unit-Test-Erstgeneration und API-Smoke-Tests aus OpenAPI-Specs. Wenn du Copilot-Workspace oder Cursor produktiv nutzt, ist TestSprite eines der wenigen Tools, die exakt diese Lücke schließen.
Testim by Tricentis
Testim (gegründet 2014, Tel Aviv) wurde 2019 von Tricentis übernommen und ist heute Teil des Tricentis-Quality-Engineering-Ökosystems neben Tosca und qTest. Die Stärke liegt in Smart-Locators: die KI baut für jedes UI-Element einen Vektor aus mehreren Eigenschaften (Position, Farbe, Text, Parent-Element). Ändert sich eine, greifen die anderen.
Im Authoring kannst du zwischen Codeless-Recorder und Custom-JavaScript wechseln, ohne das Tool zu verlassen. Das macht Testim für Hybrid-Teams attraktiv, wo Manual-Tester die Basis aufnehmen und Entwickler Custom-Validierungen ergänzen. Die Tricentis-Akquisition bringt Vorteile bei Enterprise-Integrationen: Tosca-Lizenzkunden bekommen oft Testim-Module günstig dazu und können Test-Daten zwischen den Tools sharen.
Schwächer als Applitools bei reinem Visual-Vergleich, stärker bei DOM-getriebenen Web-Apps mit dynamischen IDs. Wenn dein Team bereits im Tricentis-Stack arbeitet oder Enterprise-Support-Verträge braucht, ist Testim die kostengünstigere Option als reines Tosca-Add-on.
KaneAI by LambdaTest
KaneAI ist LambdaTests KI-natives Test-Agent-Modul, ausgerollt Mitte 2024. Der Pitch: „world's first AI-native test agent". In der Praxis heißt das: du beschreibst einen Test-Plan in Plain English, KaneAI generiert daraus konkrete Test-Cases, läuft sie auf LambdaTests Cloud-Grid (3000+ Browser/OS-Kombinationen) und liefert dir Failure-Analyse zurück.
Differenzierer gegenüber Functionize und Virtuoso: KaneAI sitzt direkt auf der LambdaTest-Cloud, was Cross-Browser-Coverage zum Default macht. Du musst keinen separaten Browser-Grid managen, kein Selenium-Grid betreiben, kein BrowserStack als Add-on einkaufen. Für Teams, die ohnehin auf LambdaTest setzen, ist KaneAI die natürliche Erweiterung.
Limitation: KaneAI ist relativ neu (1.x-Stand 2026), Enterprise-Features wie SSO, Role-Based-Access und Audit-Logs sind im Mid-Market-Tier nicht inklusiv. Für Startup- und Scale-Up-Teams ist das KI-Test-Plan-Feature aber eine der zugänglichsten Optionen am Markt.
Auswahl-Matrix: Welches Tool für welchen Use-Case
| Use-Case | Erste Wahl | Begründung |
|---|---|---|
| Visual-Regression über viele Viewports | Applitools | Marktführer Visual-AI, Universal SDK in fast jedem Framework |
| Native Desktop-Apps testen | AskUI | Vision-Modell statt DOM, deutsche Firma mit DSGVO-Klarheit |
| Manual-Tester ohne Code-Background | Virtuoso | Plain-NL-Authoring + Journey-Konzept, niedrigste Einstiegshürde |
| DevOps-Pipeline mit Auto-Heal | Mabl | Cloud-only, native CI-Integration, Gartner 4.9/5 |
| End-to-End mit Test-Daten-Generation | Functionize | Daten-Generation eingebaut, native Xray-Bridge |
| KI-generierten Code validieren | TestSprite | MCP-native, Copilot/Cursor-Integration, Pass-Rate 42→93% |
| Bestehender Tricentis-Stack erweitern | Testim | Tosca-Integration, Smart-Locator-Vektoren |
| Cross-Browser + Multi-Device | KaneAI | Native LambdaTest-Grid, 3000+ Browser-OS |
Fallstricke und Anti-Patterns
Aus der Praxis von Qytera-Projekten und aus eigenem Stack-Auswahl-Erfahrung im API-Tooling hier die fünf häufigsten Anti-Patterns bei KI-Test-Tool-Einführungen:
1. POC ohne Akzeptanzkriterien. „Wir probieren mal Applitools" endet in einem Demo-Test, der nichts beweist. Definiere vor dem POC drei Fragen: Welche Wartungsstunden willst du sparen? Welche Tests dürfen aus dem alten Framework raus? Welchen Failure-Recall braucht ihr?
2. Visual-AI statt Funktional-Tests. Visual-AI prüft nicht ob ein Button funktioniert, nur ob er aussieht wie vorher. Ein klassischer E2E-Test mit Assertion „Warenkorb-Total = 79,90 €" findet Bugs, die Visual-AI strukturell nicht sehen kann.
3. Self-Healing ohne Code-Review. Wenn die KI Selektoren austauscht, ohne dass ein Mensch das prüft, wird der Test irgendwann gegen die falsche Seite ausgeführt. Self-Heal-Diffs müssen in den Pull-Request, nicht nur ins Tool-Log.
4. NL-Tests ohne Glossar. „Klicke auf den blauen Button" funktioniert in der Demo. In der echten Anwendung gibt es drei blaue Buttons. NL-Tests brauchen ein team-internes Vokabular (semantische IDs, Domain-Begriffe), das die KI eindeutig auflöst.
5. Tool-Wechsel statt Strategie. Wer Selenium-Probleme nicht löst, löst sie auch nicht mit Mabl oder Applitools. Tool-Migration kostet 3 bis 6 Monate Team-Bandbreite. Erst Test-Strategie klären (was, wann, durch wen), dann Tool wählen.
Fazit: 2026 ist das Jahr der Hybrid-Strategien
Kein KI-Tool aus dieser Liste deckt alle Test-Stufen ab. Applitools ist stark im Visual, schwach in API-Tests. Virtuoso ist stark im Manual-Authoring, schwach bei Component-Tests. TestSprite validiert KI-Code, ersetzt aber keine E2E-Suite. Wer 2026 ernsthaft KI ins Testing bringt, kombiniert: ein Visual-AI-Tool, ein NL-Authoring-Tool, ein AI-Code-Validation-Tool, dazu klassisches Playwright oder Cypress für alles, was die KI nicht trifft.
Mein Ratschlag aus der Praxis: starte mit dem Tool, das deinen größten Schmerzpunkt löst (Wartungsstunden, fehlende Manual-Tester-Brücke, KI-Code-Qualität), nicht mit dem Tool, das die schönste Demo zeigt. Tools wechseln. Qualitätsdenken bleibt.
Wenn du tiefer in die methodischen Grundlagen einsteigen willst, sind drei interne Artikel sinnvoll: der KI-Pillar mit ISTQB CT-GenAI, der Praxis-Artikel zu ChatGPT für Testautomatisierung und unsere Beratungsleistung zu Generative AI im Testing. Wer eine Tool-Auswahl-Beratung möchte, sprich uns über die Testautomatisierungs-Beratung an.
Häufig gestellte Fragen
Ersetzen KI-Testing-Tools die Tester?
Nein. KI-Tools übernehmen Routine wie Selektor-Pflege, Daten-Generation und Visual-Diffs. Sie ersetzen weder die Testfall-Konzeption noch das fachliche Verständnis der Anwendung. In Qytera-Projekten 2025 haben KI-Tools die Wartungs-Stunden um 30 bis 50 Prozent gesenkt, die Konzeptions- und Risiko-Bewertungsstunden aber nicht reduziert.
Gibt es Open-Source-Alternativen zu Applitools und Mabl?
Begrenzt. Im Visual-Bereich nähern sich Tools wie BackstopJS, Playwright-Visual-Comparisons und Percy (mittlerweile BrowserStack) an, allerdings ohne die semantische AI-Bewertung. Für Self-Healing bietet Cypress mit dem cypress-real-events-Plugin Teil-Self-Heal, ist aber kein Ersatz für die Funktionize-Pipeline. Wer 2026 wirklich KI-Power braucht, kommt um proprietäre Tools nicht herum.
Macht ein KI-Tool neben Playwright oder Selenium Sinn?
Ja, die Kombination ist Standard. Klassische Frameworks (Playwright, Selenium, Cypress) bleiben für Component- und Smoke-Tests im CI. KI-Tools übernehmen Visual-Regression, Cross-Browser-Coverage und Wartungs-Reduktion bei den 10 bis 20 kritischen User-Journeys. Beide Layer parallel sind günstiger als doppelte Wartung.
Welches Tool ist DSGVO-konform und in Deutschland nutzbar?
Alle hier vorgestellten Tools können in EU-Regionen betrieben werden. AskUI ist deutsche Firma (Heidelberg) und damit besonders einfach für Audit und Auftragsverarbeitung. Applitools, Mabl, Functionize und Testim bieten EU-Datenregionen. KaneAI läuft auf LambdaTest und braucht eine separate EU-Region-Anfrage. Klär in jedem Fall vorher mit Datenschutz, ob Test-Daten echte Personendaten enthalten dürfen.
Was kosten KI-Testing-Tools 2026 typischerweise?
Die Preisspanne ist groß. Startup-freundliche Tools wie TestSprite beginnen unter 100 Euro pro Entwickler und Monat. Mid-Market wie Mabl, Virtuoso oder AskUI liegt bei mehreren hundert Euro pro Test-Engineer und Monat. Enterprise-Optionen wie Applitools, Functionize oder Testim sind oft Jahresverträge im fünf- bis sechsstelligen Bereich. Faustregel: Self-Healing rechnet sich ab etwa 200 Test-Cases im Bestand. Darunter sind die Lizenzkosten höher als die gesparte Wartung.
Wie führe ich ein KI-Testing-Tool im Team ein?
Drei Schritte, die in Qytera-Projekten funktioniert haben: (1) Schmerzpunkt benennen (Wartungsstunden, fehlende Manual-Tester-Brücke, KI-Code-Qualität), (2) Vier-Wochen-Pilot mit Akzeptanzkriterien (Wartung-Stunden vorher/nachher, Failure-Recall, Tester-Akzeptanz), (3) Hybrid-Roll-Out: nur die kritischen 20 Prozent der Tests ins KI-Tool, der Rest bleibt im bestehenden Stack. Tool-Komplett-Migration ohne Schmerzpunkt-Validierung scheitert in der Regel.