Angesichts einer sich rapide wandelnden Technologielandschaft und gestiegener Kundenerwartungen sieht sich die Automobilindustrie mit einer Vielzahl von Herausforderungen konfrontiert. Eine Kernherausforderung ist die effektive Implementierung der Prinzipien kontinuierlicher Integration und kontinuierlicher Bereitstellung (CI/CD) innerhalb einer komplexen Multi-Projekt-Umgebung von mechatronischen Systemen mit Anbindung von Hardware-Software-Integrationstests und unter Anwendung diverser Standards und Normen der Branche.
Wiederverwendbarkeit und Software-Produktlinien
Ein zentraler Aspekt der Automobilindustrie ist die Wiederverwendbarkeit von gemeinsam genutzten Artefakten. Bei klassischen Ingenieurtätigkeiten spricht man häufig von Produktfamilien oder Plattformen. Solche Produktfamilien sind bei der Hardwareherstellung bereits Gang und Gäbe, in der eingebetteten Softwareentwicklung in Form von Software-Produktlinien aber immer noch zu schwach ausgeprägt. Hierbei handelt es sich nicht nur um eine gemeinsame Codebasis, die zwischen zahlreichen Projekten geteilt wird, sondern auch um wiederverwendbare Anforderungen, Architekturen und Tests.
Die Vorteile der Wiederverwendbarkeit sind mannigfaltig: Sie reduziert sowohl die Entwicklungszeit als auch die Kosten und minimiert gleichzeitig die Risiken, die mit der Neuentwicklung verbunden sind. Anforderungen, die in der Konzeptphase festgelegt werden, können in diversen Projekten wiederverwendet und angepasst werden, was die Effizienz des gesamten Entwicklungsprozesses steigert. So können beispielsweise mehrere Projekte gleichzeitig beginnen, nämlich mit der geteilten Basis, ohne dass dafür ein größeres Team benötigt wird. Allerdings führt dies auch zu einer erhöhten Komplexität in der Anforderungsanalyse und -verwaltung. Durch die Verwendung bereits getesteter und validierter Komponenten kann die Qualität des Endprodukts signifikant verbessert werden.
Des Weiteren senkt die Wiederverwendung den Wartungsaufwand für alle beteiligten Artefakte. Ein klassischer Clone-and-Own-Ansatz würde im Laufe der Zeit zu einer zunehmenden Divergenz zwischen den Artefakten verschiedener Projekte führen, da unterschiedliche Teams oft unterschiedliche Implementierungen für ähnliche Anforderungen entwickeln, die dann nicht ineinander übergehen würden. Dies alles ermöglicht es Unternehmen, agiler auf Marktanforderungen zu reagieren und somit einen Wettbewerbsvorteil gegenüber Mitbewerbern zu erzielen, die jedes Projekt von Grund auf neu oder für sich betrachtet entwickeln und testen.
Es ist jedoch wichtig zu unterstreichen, dass nicht alle Elemente zwischen den Projekten geteilt werden können oder sollen. Auf dem stark umkämpften Markt der Automobilindustrie streben viele Kunden nach einzigartigen Features, um sich von der Konkurrenz abzuheben. Diese Notwendigkeit führt oft zu einer Vielzahl von Sonderlösungen, was die Komplexität auf Seiten der Zulieferer beträchtlich erhöht – auch innerhalb der ansonsten wiederverwendeten Artefakte. Dennoch ist die durch Wiederverwendung induzierte Komplexität im Allgemeinen geringer als die, die bei einer Clone-and-Own-Strategie entstehen würde.
Insbesondere die CI/CD-Pipelines (erstellt mit Jenkins , Github Actions oder ähnliche) und deren zugrunde liegende Build-Systeme und Infrastrukturen profitieren von Produktfamilien und sind von kundenspezifischen Wünschen nur sehr gering betroffen. Denn die zu erzeugenden Ergebnisse, wie Binär-Dateien und Reports, oder auch die benötigten Qualitätssicherungswerkzeuge, Standards und Normen sind in der Regel für alle Kundenprojekte einer Familie identisch. Das kann den Entwicklungsaufwand von unterstützenden Tools und Prozessen um ein vielfaches reduzieren.
Integration
Die Wiederverwendung von Code und Tests ermöglicht es, Softwarekomponenten, Testfälle und -szenarien effizient in mehreren Projekten einzusetzen. Dieser Ansatz ist zwar wirtschaftlich attraktiv, birgt jedoch eine Reihe von Herausforderungen. Insbesondere hat jede Modifikation einer geteilten Codekomponente oder eines Testfalls das Potenzial, weitreichende Auswirkungen auf alle Projekte zu haben, die diese Elemente verwenden. Daraus ergibt sich die Notwendigkeit für Entwickler und Integratoren gleichermaßen, ein robustes Abhängigkeitsmanagement zu implementieren oder Änderungen immer in allen möglichen Varianten mit Hilfe automatischer Tests zu prüfen.
Teilweise ist es sehr kompliziert, festzustellen, in welchen Projekten eine Änderung tatsächlich aktiv ist, wodurch es vorkommen kann, dass eine Änderung in allen Projekten getestet werden muss, was zusätzliche Zeit kosten kann. Die Integratoren müssen zusammen mit den Komponentenverantwortlichen und Softwareprojektleitern alle Konfigurationen im Blick behalten und sicherstellen, dass jedes Projekt entsprechend der Anforderungen konfiguriert ist. Denn der Code (Configurable Sources) ist nicht mehr die alleinige Wahrheit.
Erst zusammen mit der Projektkonfiguration (Configured Sources) und der Parametrisierung ergibt sich das Gesamtprodukt. Der Umfang an konfiguriertem Code ist in Software-Produktlinien auf Sicht eines einzelnen Projekts größer als in Clone-and-Own, auf Sicht der gesamten Produktlinie jedoch kleiner. Tools wie FeatureIDE oder Kconfig können in Verbindung mit Build-Tools (wie Make - GNU Project - Free Software Foundation oder CMake ) oder Präprozessor-Direktiven helfen, den Code konfigurierbar zu gestalten. Solche Entwicklungswerkzeuge sind in der Regel auf einen Einsatz in CI/CD-Umgebungen ausgelegt und lassen sich problemlos automatisieren.
Pipeline Automatisierung
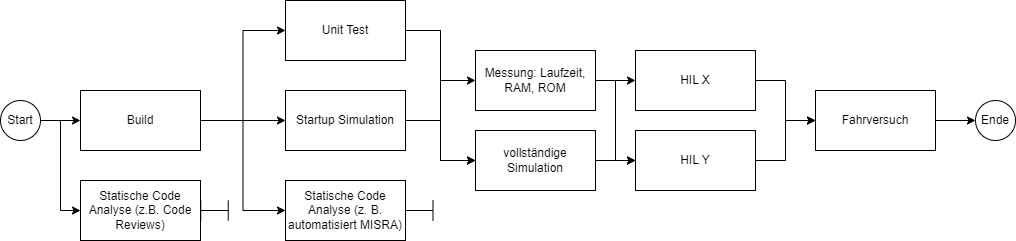
Flächendeckende Automatisierung ist wichtig, nicht nur bei den Builds, sondern auch beim Testen. Aber jede Automatisierung bringt wenig, wenn sie ewig dauert. Wir schaffen eine weitere Ebene der Komplexität aus der Notwendigkeit heraus, dass Builds und Tests in angemessener Zeit abgeschlossen werden müssen - "Fail Fast" ist die Devise.
Alleine das Kompilieren und Linken kann aufgrund der vielen Optimierungsschritte im Embedded-Bereich bereits über eine Stunde dauern. Die Hardware wird mit minimalen Ressourcen (RAM, ROM, Laufzeit) entworfen, denn sie wird in extrem hohen Stückzahlen verkauft und soll möglichst viel Gewinn erwirtschaften. Die Software hingegen wird einmal entwickelt und auf beliebig vielen Steuergeräten vertrieben und muss genau auf diese Ressourcen-Einschränkungen hin optimiert und selbstverständlich auch (automatisch) getestet werden. Nicht-funktionale Tests u.a. für Ressourcenverbrauch sind essentiell und können kontinuierlich überprüfen, ob die Hardware und Software in einer möglichst günstigen Kombination noch zusammenpassen. Umfangreiche Builds und komplette Testdurchläufe (funktional und nicht-funktional) können hier trotz Automatisierung leicht 24h dauern.
Mögliche automatisierbare Tests sind:
- Statische Analysen (Coding-Regeln, Best-Practices)
- Dynamische Analysen wie Wertebereichsüberprüfung zum Ausschließen von Division durch 0 (u. a.)
- Unit-Tests
- Tests für Ressourcenverbrauch (RAM, ROM, Laufzeit)
- Software-Integrations-Tests (Software-Software-Integration für die Überprüfung von Signalketten)
- Software-Systemtest (Simulationen auf dem Entwickler-PC, simulierte Anschalttests und vollständige Simulation von Fahrmanövern)
- Software-Hardware-Integrations-Tests (Die Software im Verbund mit der Hardware testen)
Im Falle statischer Code-Analysen, also unter anderem das Prüfen auf MISRA C-Regeln (Motor Industry Software Reliability Association) oder HIS-Metriken (Herstellerinitiative Software, einige Beispiele für Metriken gibt es hier: HIS Source Code Metrics - Emenda), können vollständige Testläufe wegen der Konfigurierbarkeit sogar noch mehr Zeit beanspruchen. Dadurch haben sich in einigen Firmen die sogenannten täglichen Nightly-Builds, also eine nächtliche Überprüfungen verschiedener Qualitätsstufen nach der Integration, etabliert und lange gehalten. Eine tatsächliche kontinuierliche Integration ist vielfach sehr schwer, aber notwendig.
Deswegen ist es unumgänglich, dass mehrere Prozesse parallel laufen müssen und, dass Prozesse wo immer möglich inkrementell arbeiten, um die Agilität des Entwicklungszyklus aufrechtzuerhalten. Inkrementell bedeutet in diesem Zusammenhang auch, dass langwierige Prozesse gar nicht erst gestartet werden sollten, wenn durch frühere, schnellere Tests bereits absehbar ist, dass sie keinen Erfolg haben werden oder keinen neuen Beitrag leisten. Im Falle von neuen Änderungen, können, wenn möglich, auch nur die Änderungen getestet und betroffene Tests durchgeführt werden, um Zeit zu sparen. Für Freigaben können dann wiederum automatisierte Regressionstests auf der gesamten Code-Basis durchgeführt werden. Für solche Fälle sind mehrstufige CI/CD-Pipelines wichtig und beispielhaft in der Grafik dargestellt: