

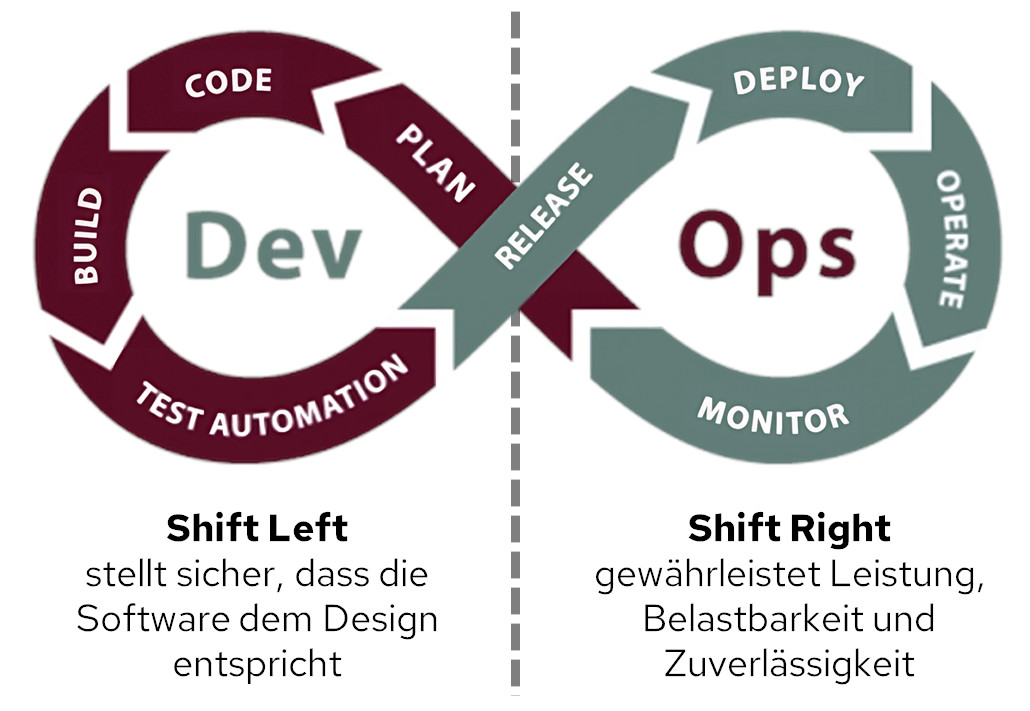
Wer Softwarequalität heute ernst nimmt, kommt an zwei Begriffen nicht vorbei: Shift Left Testing und Shift Right Testing. Beide Paradigmen verschieben den Fokus der Qualitätssicherung weg vom klassischen Testfenster am Ende der Entwicklung: Shift Left nach vorne in Design und Code, Shift Right nach hinten in Betrieb und reale Nutzung. In der Praxis schließen sich die Ansätze nicht aus, sondern ergänzen sich zu einer durchgängigen Quality-Engineering-Strategie.
Wir haben in den letzten Jahren bei Kundenprojekten beobachtet, dass Teams oft nur Shift Left adressieren und Shift Right als „Monitoring-Sache" an den Betrieb auslagern. Damit verschenken sie wertvolles Feedback aus Produktion. Dieser Beitrag zeigt, wie beide Welten zusammenpassen, welche Tools 2026 relevant sind und wo die Verantwortlichkeit von Testern in einer DevTestOps-Organisation liegt.
Der Fokus liegt auf Praxis: Definitionen werden knapp gehalten, der Schwerpunkt liegt auf Tools, Tabellen und konkreten Beispielen, die Sie in Ihren Projekten anwenden können.
Inhaltsverzeichnis
- Was ist Shift Left Testing?
- Was ist Shift Right Testing?
- Shift Left vs. Shift Right im Direktvergleich
- Testpyramide, Trophy oder Honeycomb?
- Shift-Left-Tools: Vom Komponententest bis zum Pipeline-Gate
- Shift-Right-Tools: Observability, Feature Toggles und Chaos
- Praxis: Azure Deployment Slots und Canary Releases
- DevTestOps: Tester-Rolle links und rechts der Pipeline
- KI-getriebene Shift-Left-Tests 2026
- Fazit
- FAQ: Häufige Fragen zu Shift Left und Shift Right
Was ist Shift Left Testing?
Shift Left Testing bedeutet, Qualitätssicherung so früh wie möglich im Entwicklungsprozess zu verankern. Statt erst am Ende eines Sprints oder einer Iteration zu prüfen, wandern Test- und Review-Aktivitäten in die Anforderungs-, Design- und Implementierungsphase. Klassische Bausteine sind Test-Driven Development (TDD), statische Codeanalyse, Komponententests (Unit-Tests), Integrationstests sowie automatisierte Quality Gates in der CI/CD-Pipeline.
Der Hebel ist ökonomisch: Ein Fehler, der in der Designphase entdeckt wird, kostet ein Vielfaches weniger als derselbe Fehler in Produktion. Studien des IBM Systems Sciences Institute schätzen den Faktor auf 6 bis 100. Wichtiger als die exakte Zahl ist die Mechanik: Je später ein Defekt gefunden wird, desto mehr nachgelagerte Artefakte (Tests, Doku, Schulungen, abhängige Komponenten) müssen angepasst werden.
Shift Left ist eng mit agilen Vorgehensmodellen und der DevOps-Bewegung im Performance Testing verbunden. Continuous Testing, also das automatisierte Ausführen aller Testebenen bei jeder Code-Änderung, ist die operative Umsetzung des Paradigmas.
Was ist Shift Right Testing?
Shift Right Testing verlagert die Qualitätsperspektive in den Betrieb. Statt nur vor dem Go-Live zu testen, beobachten und prüfen Teams die Anwendung im Produktivbetrieb mit echten Nutzerinnen und Nutzern, realistischer Last und vollständiger Infrastruktur. Das ist kein Verzicht auf Tests vor Release, sondern eine Erweiterung: Manche Risiken zeigen sich erst unter Produktionsbedingungen.
Typische Shift-Right-Bausteine sind Observability (Logs, Metriken, Traces), Feature Toggles, A/B-Testing, Canary Releases, Chaos Engineering und Resilienz-Tests. Die Grundannahme: Eine produktionsnahe Umgebung ist nicht Produktion. Last, Datenvolumen, Netzwerk-Topologie und Nutzerverhalten lassen sich nie hundertprozentig nachstellen.
Shift Right ist die natürliche Ergänzung zu DevOps-Praktiken wie Continuous Deployment und Cloud-nativen Architekturen. Wenn Teams mehrmals täglich deployen, wird das Release selbst zum Test. Die Frage lautet nicht mehr „Ist die Software fehlerfrei?", sondern „Welche Probleme treten unter realen Bedingungen auf und wie schnell erkennen wir sie?".
Shift Left vs. Shift Right im Direktvergleich
Beide Paradigmen adressieren unterschiedliche Risiken und ergänzen sich. Die folgende Tabelle stellt die wichtigsten Unterschiede gegenüber:
| Aspekt | Shift Left Testing | Shift Right Testing |
|---|---|---|
| Zeitpunkt | Anforderung, Design, Implementierung | Staging, Produktion, Betrieb |
| Ziel | Fehler verhindern, früh erkennen | Reales Verhalten beobachten, Resilienz prüfen |
| Datenbasis | Synthetisch, Testdaten | Echte Nutzerdaten, Produktionslast |
| Typische Methoden | TDD, Unit-Tests, statische Analyse, Code-Review | Monitoring, Chaos Engineering, A/B-Tests, Canary |
| Feedback-Latenz | Sekunden bis Minuten | Stunden bis Tage |
| Kosten pro Fehlerfund | Niedrig | Höher (Rollback, Hotfix, Image-Schaden) |
| Tester-Rolle | Pair-Testing, Test-Design im Refinement | SRE-nah, Observability, Postmortem-Beteiligung |
| Erfolgsmessung | Defect-Density, Coverage, Build-Stabilität | MTTR, Error-Budget, Service Level Indicators |
In der Praxis ist die Frage nicht „entweder oder", sondern „wie viel Gewicht je Phase". Sicherheitskritische Domänen wie Medizintechnik oder Bahn setzen Schwerpunkte links. Web-Anwendungen mit hoher Release-Frequenz nutzen oft eine Mischung mit deutlichem Shift-Right-Anteil.
Testpyramide, Trophy oder Honeycomb?
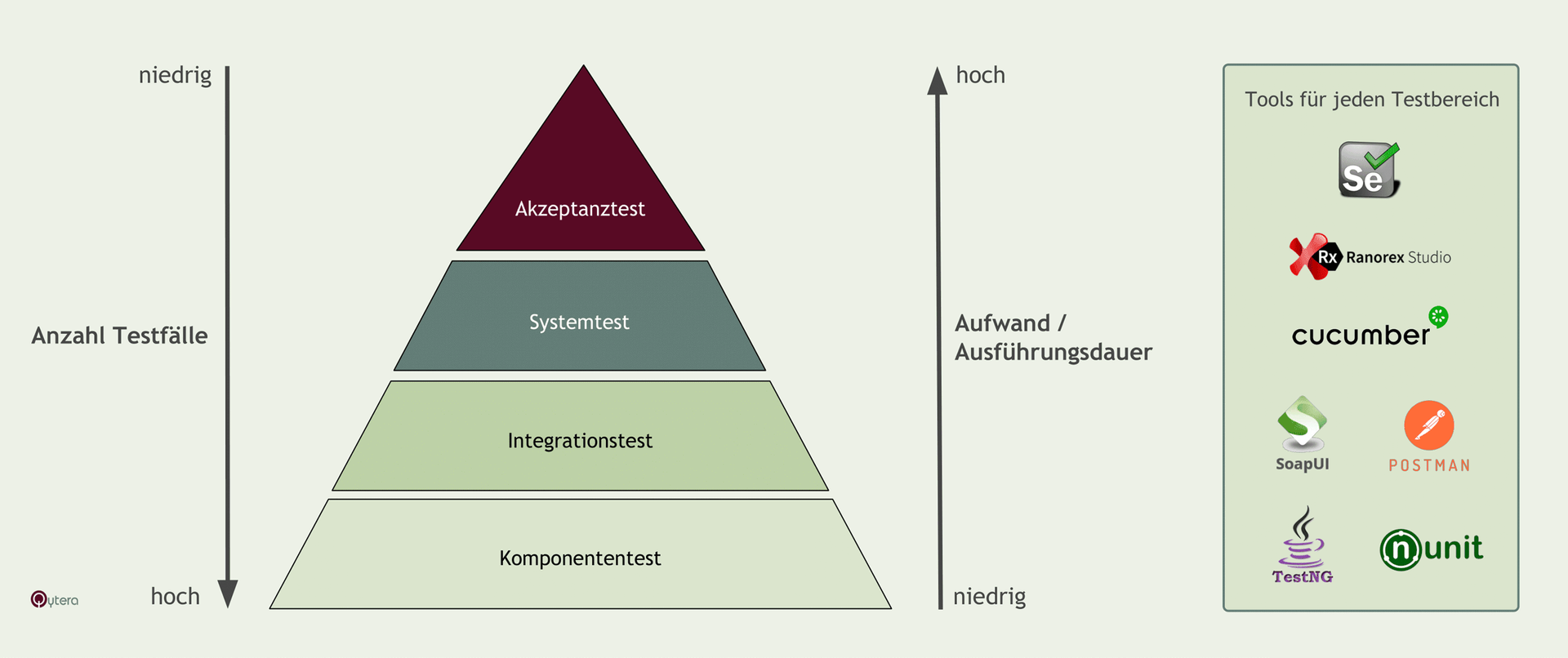
Die klassische Testpyramide nach Mike Cohn (2009) ist nach wie vor die verbreitetste Heuristik für Shift-Left-Strategien: viele schnelle Komponententests an der Basis, weniger Integrationstests in der Mitte, wenige Ende-zu-Ende-Tests (E2E) an der Spitze. In modernen Microservice-Architekturen stoßen Teams jedoch auf Grenzen, weil viele Defekte erst an Service-Grenzen auftreten.
Drei prominente Alternativen haben sich etabliert:
- Test-Trophy (Kent C. Dodds, 2018): Static Checks (Linting, Typprüfung), Komponententests, Integrationstests als Schwerpunkt, wenige E2E-Tests. Reaktion auf TypeScript-Welt und React-Komponententests.
- Test-Honeycomb (Spotify Engineering): Wenige Integrierte Tests an Service-Grenzen, viele Integrationstests innerhalb des Service, wenige isolierte Komponententests. Optimiert für Microservices mit hoher Service-Anzahl.
- Test-Diamond: Schwerpunkt Integrationstests, weniger Unit- und E2E-Tests. Häufig bei API-First-Produkten.
Welche Form passt, hängt von Architektur, Team-Größe und Risikoprofil ab. Für eine pragmatische Bewertung empfehlen wir, die Verteilung Ihrer existierenden Tests zu vermessen (Anzahl, Laufzeit, Fehlerfund-Rate je Ebene) und mit der Heuristik zu vergleichen. Mehr zu Teststrategien finden Sie in unserem Testkonzept-Leitfaden und in den 10 goldenen Regeln im Testmanagement.
Shift-Left-Tools: Vom Komponententest bis zum Pipeline-Gate
Shift Left lebt von Automatisierung. Ohne Werkzeuge, die in jeder CI-Pipeline laufen, verkommt das Paradigma zu Lippenbekenntnissen. Die folgende Tabelle ordnet typische Toolkategorien den Pipeline-Stages zu:
| Pipeline-Stage | Kategorie | Beispiel-Tools | Quality Gate |
|---|---|---|---|
| Pre-Commit | Linting, Format, Type-Check | ESLint, Prettier, mypy, ktlint | 0 Fehler |
| Build | Komponententests | JUnit, pytest, Jest, Vitest | Coverage ≥ 80% |
| Build | Statische Codeanalyse (SAST) | SonarQube, Semgrep, CodeQL | 0 kritische Findings |
| Build | Dependency-Scan (SCA) | Snyk, Dependabot, OWASP DC | 0 High/Critical CVEs |
| Integration | Integrationstests | REST Assured, Testcontainers | 100% grün |
| Integration | Contract-Tests | Pact, Spring Cloud Contract | Kompatibilität bestätigt |
| Pre-Deploy | E2E-Tests (Smoke) | Playwright, Cypress | Kritische Pfade grün |
| Pre-Deploy | Performance-Smoke | k6, JMeter, Gatling | p95 unter SLO |
| Pre-Deploy | DAST | OWASP ZAP, Burp Suite | 0 High-Findings |
Wichtig ist die Reihenfolge: Schnelle Tests zuerst, langsame zuletzt. Wer einen 20-minütigen E2E-Test vor dem ESLint-Lauf platziert, verliert Entwicklungs-Geschwindigkeit. Die Faustregel lautet: Tests, die in wenigen Sekunden laufen, gehören auf jeden Push; Tests im Minutenbereich auf jeden Merge; Tests im Stundenbereich auf einen Nightly-Build.
name: quality-gate
on: [push, pull_request]
jobs:
lint-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Lint
run: npm run lint
- name: Type-Check
run: npm run typecheck
- name: Unit-Tests + Coverage
run: npm test -- --coverage
- name: SAST (Semgrep)
uses: returntocorp/semgrep-action@v1
Shift-Right-Tools: Observability, Feature Toggles und Chaos
Shift Right braucht andere Tools als Shift Left. Statt synthetischer Tests stehen Beobachtbarkeit und kontrollierte Experimente im Vordergrund. Die folgende Übersicht ordnet Werkzeuge ihrem primären Einsatzzweck zu:
| Bereich | Tool-Beispiele | Einsatzzweck |
|---|---|---|
| Logs, Metriken, Traces | Prometheus, Grafana, Loki, ELK, OpenTelemetry | Anomalien erkennen, Service-Gesundheit messen |
| Application Performance Monitoring | Datadog APM, New Relic, Dynatrace, AppDynamics | Latenz pro Endpoint, Fehler-Hot-Spots |
| Feature Toggles | LaunchDarkly, Unleash, ConfigCat, Flagsmith | Feature-Rollout per Nutzer, Region, Prozent |
| A/B-Testing | Optimizely, Statsig, GrowthBook | Hypothesen über Nutzerverhalten validieren |
| Canary Releases | Argo Rollouts, Flagger, Spinnaker | Schrittweises Hochfahren neuer Versionen |
| Chaos Engineering | Chaos Monkey, LitmusChaos, Gremlin, Steadybit | Resilienz unter Ausfällen prüfen |
| Synthetic Monitoring | Checkly, Datadog Synthetics, Grafana k6 | Kritische Pfade aus Produktion durchspielen |
| Session-Replay | FullStory, Hotjar, LogRocket | Echte Nutzerinteraktionen rekonstruieren |
Die Auswahl orientiert sich an Architektur und Reifegrad. Kleinere Teams starten häufig mit Prometheus plus Grafana und einem Feature-Toggle-Tool, bevor sie Chaos Engineering einführen. Größere Organisationen kombinieren APM-Suite, dediziertes A/B-Framework und mehrere Toggle-Ebenen (Operator-Toggle, Experiment-Toggle, Release-Toggle).
Eine Tiefenanalyse zu APM finden Sie im Beitrag Application Performance Monitoring.
Praxis: Azure Deployment Slots und Canary Releases
Ein konkretes Beispiel für Shift Right sind Azure Deployment Slots im App-Service. Sie erlauben es, eine neue Version in einer Staging-Slot-Umgebung mit Produktions-Infrastruktur zu deployen, dort Tests durchzuführen und anschließend per Swap atomar die Rollen mit der Production-Slot zu tauschen. Bei Problemen kann der Swap binnen Sekunden zurückgenommen werden.
Der Praxis-Ablauf sieht typischerweise so aus:
- Build der neuen Version per CI/CD-Pipeline (Shift Left: alle Quality Gates grün).
- Deployment in einen Staging-Slot mit Production-DB-Connection-String, aber abgekoppelt.
- Smoke-Tests gegen den Staging-Slot (Playwright, Synthetic Monitoring).
- Traffic-Routing: 10 Prozent des Produktions-Traffics auf den Staging-Slot.
- Observability-Check (Fehlerquote, Latenz, Geschäfts-Metriken).
- Wenn grün: Swap auf 100 Prozent. Wenn rot: Traffic zurück auf alten Slot.
Dasselbe Muster setzen Kubernetes-Anwender mit Argo Rollouts oder Flagger um, AWS-Teams mit CodeDeploy und Lambda-Aliasen. Der gemeinsame Nenner ist immer: Eine neue Version sieht Produktionslast, bevor sie 100 Prozent der Nutzer erreicht.
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: web-frontend
spec:
strategy:
canary:
steps:
- setWeight: 10
- pause: { duration: 5m }
- setWeight: 25
- pause: { duration: 10m }
- setWeight: 50
- pause: { duration: 15m }
- setWeight: 100
analysis:
templates:
- templateName: success-rate
DevTestOps: Tester-Rolle links und rechts der Pipeline
In klassischen Teams trennten Entwicklung, Test und Betrieb klare Aufgabenbereiche. DevTestOps löst diese Trennung auf: Tester verantworten Qualität über den gesamten Lebenszyklus. Konkret bedeutet das eine erweiterte Rollenbeschreibung:
- Im Refinement (Shift Left): Teilnahme an Story-Refinement, Ableitung von Akzeptanzkriterien, Test-Design vor Entwicklung. Kollaboration mit Entwicklern via Pair-Testing.
- Im Sprint (Shift Left): Pflege der Komponententest-Strategie, Mitarbeit an Integrationstests, Review von SAST- und DAST-Findings.
- Beim Release (Mitte): Verantwortung für Quality Gates, Freigabe-Entscheidung anhand definierter Kriterien, Risiko-Kommunikation Richtung Product Owner.
- Nach Release (Shift Right): Monitoring kritischer User-Journeys, Auswertung A/B-Tests, Mitarbeit an Postmortems, Speisen der Test-Suite mit Erkenntnissen aus Produktion.
Tester werden so vom End-of-Sprint-Bottleneck zum Quality-Coach. Voraussetzung ist Toolkenntnis auf beiden Seiten: Versionsverwaltung, CI-Pipeline-Definitionen, Container, Beobachtbarkeit. Tiefer eingeordnet ist diese Rolle in unserem Beitrag Rolle des Testers in Scrum und SAFe und im Agiles Testmanagement in CI/CD.
KI-getriebene Shift-Left-Tests 2026
Mit der Verfügbarkeit leistungsfähiger Sprachmodelle hat sich Shift Left 2025 und 2026 nochmals verändert. Drei Felder sind besonders relevant:
- Test-Generierung: Tools wie GitHub Copilot, Cursor oder spezialisierte Test-Generatoren (Diffblue Cover, EarlyAI) erzeugen aus Code Komponententest-Skelette. Die Tests sind nicht perfekt, ersparen aber Boilerplate und zwingen Entwickler zum Nachdenken über Edge Cases.
- KI-gestützte Code-Reviews: PR-Bots prüfen Pull Requests auf Stil, Sicherheit und Logikfehler. Im Gegensatz zu klassischem SAST verstehen sie Kontext und liefern weniger Falschmeldungen.
- Anforderungs-Validierung: LLMs prüfen User Stories auf Vollständigkeit und Testbarkeit. Hierdurch verschiebt sich Quality-Engineering noch weiter nach links, in die Backlog-Pflege.
Vorsicht ist bei Halluzinationen geboten. Eine KI-erzeugte Testsuite ist eine Hypothese, kein Ergebnis. Wir empfehlen, KI-Vorschläge als ersten Entwurf zu verwenden, jeden Test manuell zu prüfen und insbesondere Negativ- und Grenzfälle bewusst nachzuziehen. Eine ausführliche Einordnung finden Sie in unseren Beiträgen zur ISTQB-Zertifizierung AI Testing und zum Agentic AI Testing.
Fazit
Shift Left und Shift Right sind keine konkurrierenden Ansätze, sondern zwei Hälften derselben Quality-Engineering-Strategie. Shift Left verhindert Fehler, Shift Right deckt auf, was synthetische Tests nicht abdecken können. Wer beide Welten verbindet und Tester über den gesamten Lebenszyklus verantwortlich macht, kommt zu einer realistischen, datengetriebenen Qualitäts-Sicherung.
Für eine erfolgreiche Umsetzung empfehlen wir drei Schritte: Erstens, eine Bestandsaufnahme der heutigen Testverteilung über alle Stages (Shift-Left-Reifegrad). Zweitens, einen kleinen Shift-Right-Pilot mit Feature Toggles oder Canary Releases auf einem unkritischen Service. Drittens, eine schrittweise Erweiterung der Tester-Rolle in Richtung Observability und Postmortem-Beteiligung. Wenn Sie Unterstützung bei der Einführung benötigen, sprechen Sie uns gern an.
FAQ: Häufige Fragen zu Shift Left und Shift Right
Was ist der Unterschied zwischen Shift Left und Shift Right Testing?
Shift Left verlagert Tests in frühe Phasen (Anforderung, Design, Implementierung) mit synthetischen Daten und schnellen Feedback-Schleifen. Shift Right erweitert die Qualitätssicherung in den Produktivbetrieb und nutzt Monitoring, Feature Toggles und Canary Releases. Beide Ansätze ergänzen sich. Nähere Details finden Sie im Direktvergleich oben.
Welche Tools eignen sich für Shift Left Testing?
Typische Werkzeuge sind JUnit, pytest und Jest für Komponententests, SonarQube und Semgrep für statische Analyse, Snyk für Dependency-Scans sowie Playwright und Cypress für E2E-Smoke-Tests. Performance-seitig kommen k6, JMeter und Gatling ins Spiel, idealerweise als Pipeline-Gate.
Wie führe ich Shift Right Testing pragmatisch ein?
Beginnen Sie mit Observability: Prometheus plus Grafana für Metriken, ELK oder Loki für Logs. Ergänzen Sie ein Feature-Toggle-Tool wie LaunchDarkly oder Unleash, um Releases von Deployments zu entkoppeln. Erst danach lohnen sich Canary Releases mit Argo Rollouts oder Flagger und Chaos Engineering mit LitmusChaos.
Was sind Azure Deployment Slots im Shift-Right-Kontext?
Azure Deployment Slots sind voll gemanagte Slot-Umgebungen im App-Service, in denen eine neue Version mit Produktions-Infrastruktur getestet werden kann. Per Swap wird sie atomar zur Produktiv-Version. Sie eignen sich für Blue-Green-Deployments und prozentuale Canary-Releases ohne komplexe Cluster-Konfiguration.
Wie verändert sich die Tester-Rolle durch DevTestOps?
Tester werden vom End-of-Sprint-Prüfer zum Quality-Coach mit Verantwortung über den gesamten Lebenszyklus: Test-Design im Refinement, Pflege der Automatisierung im Sprint, Quality-Gate-Verantwortung beim Release, Monitoring kritischer User-Journeys und Postmortem-Mitarbeit. Tiefer eingeordnet im Beitrag Rolle des Testers in Scrum und SAFe.
Lohnt sich Shift Right wirtschaftlich?
Ja, in den meisten Fällen. Die Kosten für Observability- und Feature-Toggle-Tools werden durch reduzierte Hotfix-Aufwände, schnellere MTTR und bessere Release-Qualität schnell ausgeglichen. Bei sicherheitskritischen Domänen (Medizintechnik, Bahn) bleibt der Schwerpunkt links, Shift Right dient dann primär der Risikoabsicherung.
Wie unterstützt KI das Shift Left Testing?
KI hilft bei der Generierung von Komponententests, beim Review von Pull Requests auf Stil und Sicherheit sowie bei der Validierung von User Stories auf Testbarkeit. KI-Tests sind ein erster Entwurf, kein Ersatz für menschliches Test-Design. Insbesondere Negativ- und Grenzfälle müssen manuell ergänzt werden. Mehr dazu im Beitrag zur ISTQB-AI-Testing-Zertifizierung.