

Software bereitzustellen ist einfach. Aber ein Deployment, das reibungslos, schnell und ohne Ausfälle abläuft? Das ist die eigentliche Herausforderung. Mit Continuous Integration und Continuous Deployment (CI/CD) sind Deployments nicht nur ein technischer Prozess, sondern ein entscheidender Faktor für den Erfolg eines Projekts. Sie beeinflussen die Entwicklungszyklen, die User Experience und letztlich den Geschäftserfolg.
Doch unabhängig davon, ob eine neue Version als großes Update oder als inkrementeller Rollout veröffentlicht wird, lauern viele Stolpersteine: Ausfallrisiken, fehlerhafte Konfigurationen oder unzureichende Tests können schnell zu Problemen führen. Gleichzeitig gibt es bewährte Strategien und moderne Werkzeuge, um den Prozess sicher und effizient zu gestalten.
In diesem Praxis-Guide werfen wir einen Blick auf verschiedene Deployment-Strategien, beleuchten typische Herausforderungen und geben praktische Tipps. Denn ein guter Deployment-Prozess ist mehr als ein Klick auf den „Deploy"-Button. Es ist eine Frage von Automatisierung, Strategie und Zusammenarbeit.
Inhaltsverzeichnis
- Deployment-Strategien: Von klassisch bis modern
- Deployment für Microservices vs Monolithen
- Herausforderungen in der Praxis
- Automatisierung: CI/CD-Pipelines als Gamechanger
- Deployment Monitoring und Observability
- Best Practices und Fazit zu Deployments
- FAQ: Häufig gestellte Fragen zu Deployment-Strategien
Deployment-Strategien: Von klassisch bis modern
Nicht jedes Deployment ist gleich, und nicht jede Strategie passt zu jedem Projekt. Während einige Teams mit traditionellen Methoden arbeiten, setzen andere auf hochmoderne, flexible Ansätze. Wer sich für die richtige Deployment-Strategie entscheidet, kann Risiken minimieren, Downtime vermeiden und die Wartbarkeit seines Systems verbessern.
Dabei spielen mehrere Faktoren eine Rolle:
- Projektansatz: Agile Projekte (z. B. nach Scrum oder SAFe) profitieren oft von iterativen Deployments mit minimaler Downtime, während Wasserfall-Projekte eher auf gut geplante, weniger häufige Releases setzen.
- Architektur: Monolithische Anwendungen erfordern oft andere Deployment-Strategien als Microservices oder lose gekoppelte Systeme, bei denen einzelne Komponenten unabhängig voneinander aktualisiert werden können.
Die 5 wichtigsten Deployment-Strategien im Vergleich
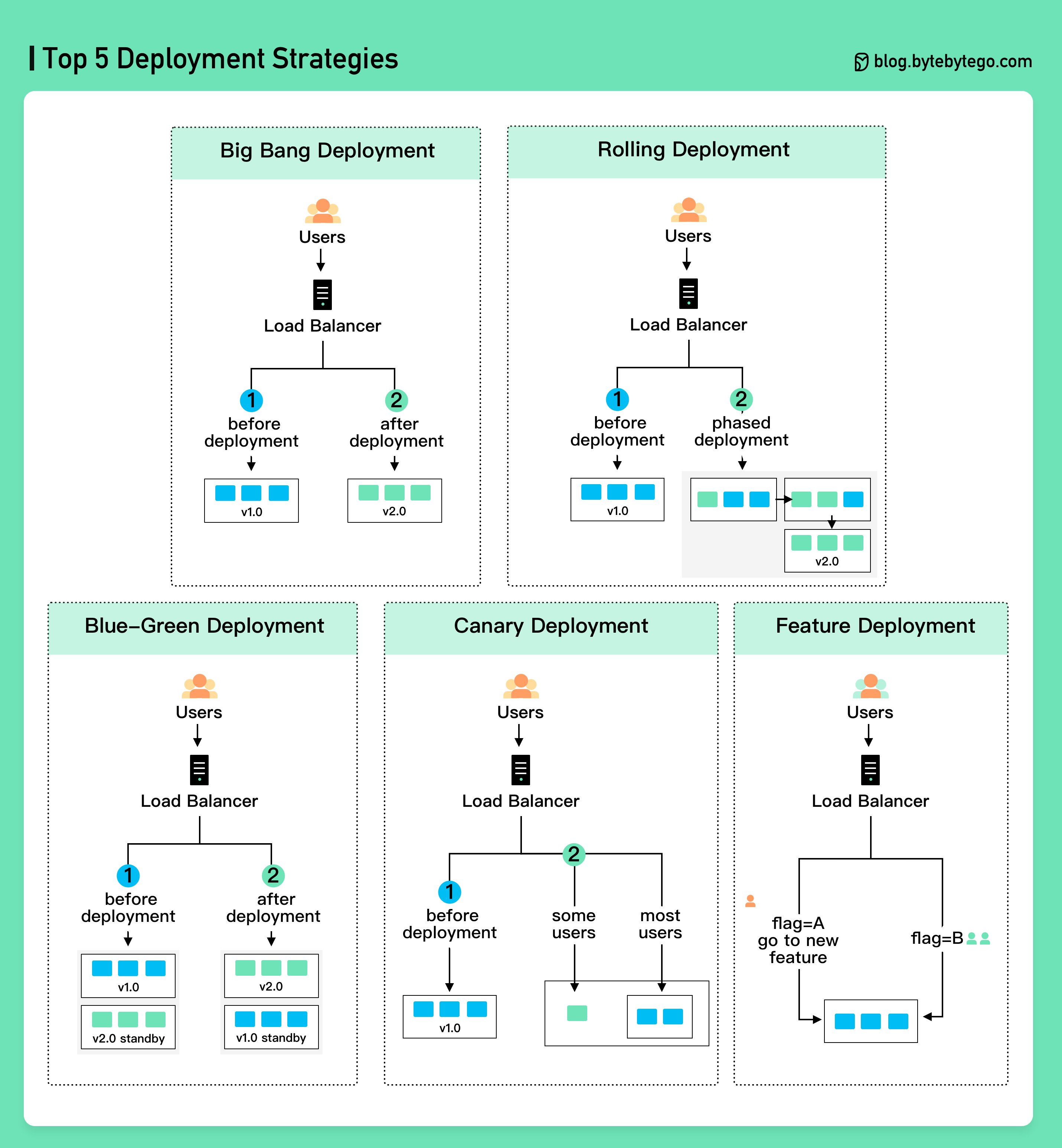
| Strategie | Downtime | Rollback | Komplexität | Kosten | Ideal für |
|---|---|---|---|---|---|
| Big Bang | Ja (geplant) | Schwierig | Niedrig | Niedrig | Monolithen, Wasserfall |
| Rolling | Keine (Zero Downtime) | Mittel | Mittel | Niedrig | Kubernetes, Microservices |
| Blue-Green | Minimal (Sekunden) | Sofort | Mittel | Hoch (doppelte Infra) | Kritische Systeme |
| Canary | Keine | Sofort | Hoch | Mittel | Große Nutzerbasis |
| Feature Toggles | Keine | Sofort (Toggle off) | Mittel | Niedrig | A/B-Tests, agile Teams |
Big Bang Deployment: Und dann kommt der Knall
Bei einem Big Bang Deployment wird die neue Version auf einmal ausgerollt, oft mit Ausfallzeiten und ohne die Möglichkeit eines schnellen Rollbacks. Diese Methode ist risikobehaftet und wird heute weniger empfohlen, da sie wenig Flexibilität bietet. Insbesondere in Cloud-Umgebungen und bei hochverfügbaren Anwendungen sind alternative Strategien sinnvoller. In klassischen Wasserfall-Projekten und bei monolithischer Codebasis ist es aber oft die einzige Option, die auch vertraglich vereinbart wird.
Rolling Deployment: Stückweise statt alles auf einmal
Hierbei wird die neue Version schrittweise über mehrere Instanzen hinweg ausgerollt, während alte Instanzen nach und nach ersetzt werden. Dies reduziert das Risiko eines fehlerhaften Deployments und ermöglicht Zero-Downtime-Updates. In Kubernetes-Umgebungen erfolgt dies oft über Rolling Updates. Einzelne Pod-Replicas bekommen ihre neuen Docker Images nach und nach.
Blue-Green Deployment: Sichere Umschaltung zwischen Versionen
Zwei Umgebungen, „Blue" (alte Version) und „Green" (neue Version), laufen parallel. Sobald die neue Version erfolgreich getestet wurde (Shift-Right-Testing), erfolgt ein Traffic-Switch zur grünen Umgebung, während die blaue als Fallback dient. Dies minimiert Downtime und erlaubt einfaches Zurückrollen im Fehlerfall.
Canary Releases: Kontrollierte Einführung mit Risikominimierung
Statt ein Deployment sofort für alle Nutzer auszurollen, wird es zunächst an eine kleine Gruppe von Nutzern ausgespielt. Erst nach erfolgreicher Validierung erfolgt das vollständige Deployment. In Kubernetes lässt sich das über Traffic-Shifting mit Service Meshes wie Istio realisieren. Besonders in Microservice-Architekturen ist diese Methode ideal, da einzelne Services unabhängig voneinander aktualisiert werden können.
Feature Toggles: Wie Releases und Deployments entkoppelt werden
Feature Toggles ermöglichen es, Features unabhängig vom Deployment zu aktivieren oder zu deaktivieren. Dadurch können neue Funktionen bereits im Code enthalten sein, aber erst dann sichtbar werden, wenn sie explizit freigeschaltet werden. Dies erlaubt A/B-Tests, schrittweise Releases und schnelle Rollbacks ohne erneutes Deployment. In agilen Projekten sind Feature Toggles besonders hilfreich, um Funktionen iterativ bereitzustellen und zu testen.
Deployment für Microservices vs Monolithen
Die Architektur entscheidet stark darüber, welche Deployment-Strategie sinnvoll ist. Monolithen und Microservices stellen unterschiedliche Anforderungen an den Bereitstellungs-Prozess.
Monolithen: Wenige Releases, viel Vorbereitung
Monolithische Anwendungen werden als eine Einheit deployed. Das vereinfacht den Build und die Konfiguration, vergrößert aber das Release-Risiko: Ein Fehler im Modul A kann die gesamte Anwendung lahmlegen. Typische Strategien sind Big Bang (klassisch, mit geplantem Wartungsfenster) und Blue-Green (für hochverfügbare Monolithen mit ausreichend Hardware-Budget). Database-Migrationen erfordern besondere Sorgfalt, weil die gesamte Codebasis gleichzeitig auf das neue Schema umsteigt.
Microservices: Viele Releases, viel Koordination
Microservice-Architekturen erlauben unabhängige Deployments pro Service. Das reduziert das Risiko pro Release, vervielfacht aber die Komplexität: 50 Services bedeuten 50 Pipelines, 50 Versionierungs-Strategien und 50 mögliche Inkompatibilitäten. Rolling Deployments sind in Kubernetes der Standard, Canary Releases für besonders kritische Services. Service-Mesh-Tools wie Istio und Linkerd vereinfachen das Traffic-Routing zwischen Service-Versionen.
In hybriden Architekturen (Monolith plus angedockte Microservices) entstehen oft die größten Reibungsverluste. Hier hilft eine klare Eigentümerschaft pro Service und eine zentrale Übersicht über laufende Deployments. Eine vertiefte Einordnung in die Test-Strategie liefert unser Artikel zu Cloud Testing.
Herausforderungen in der Praxis
Die Theorie klingt gut, die Praxis ist oft weniger elegant. Diese fünf Herausforderungen begegnen uns in fast jedem Projekt:
1. Datenbank-Migrationen
Schema-Änderungen sind der Albtraum jedes Deployments. Eine neue Spalte hinzufügen ist harmlos, eine bestehende umbenennen oder löschen kann Anwendungslogik zerstören. Bei Blue-Green Deployments muss die Datenbank beide Versionen gleichzeitig bedienen. Die Lösung: Expand-and-Contract-Pattern. Zuerst die neue Struktur hinzufügen (expand), dann die Anwendung umstellen, dann die alte Struktur entfernen (contract). Nie alles in einem Schritt.
2. Konfigurationsdrift
Staging sieht anders aus als Produktion. Andere Umgebungsvariablen, andere Secrets, andere externe Services. Was auf Staging funktioniert, kann auf Produktion scheitern. IaC (Infrastructure as Code) mit Terraform oder Ansible reduziert diesen Drift, eliminiert ihn aber nicht vollständig. Smoke-Tests nach jedem Deployment fangen die verbleibenden Unterschiede ab.
3. Abhängigkeiten zwischen Services
In Microservice-Architekturen hängt Service A von Service B ab, der wiederum von Service C abhängt. Ein Deployment von Service B ohne Rückwärtskompatibilität bricht Service A. Consumer-Driven Contract Testing (z. B. mit Pact) stellt sicher, dass API-Verträge zwischen Services eingehalten werden, bevor ein Deployment ausgerollt wird.
4. Langsame Rollbacks
Ein Rollback, der 30 Minuten dauert, ist kein Rollback. Das ist ein zweites Deployment. Rollback-Zeiten unter 5 Minuten sind das Ziel. Blue-Green Deployments erreichen das durch Traffic-Switching, Kubernetes durch Rolling Updates mit kubectl rollout undo. Wer seinen Rollback nicht regelmäßig übt, hat in der Krise keinen.
5. Feature-Abhängigkeiten von Datenbankzuständen
Neue Features setzen oft Daten voraus, die erst migriert werden müssen. Wird das Feature vor der Migration deployed, sehen Nutzer leere Seiten oder Fehlermeldungen. Deployment-Reihenfolge planen: Erst Migration, dann Feature aktivieren (Feature Toggle).
Automatisierung: CI/CD-Pipelines als Gamechanger
Deployments gehören automatisiert. Manuelle Prozesse sind nicht nur fehleranfällig und zeitaufwendig, sondern oft auch der größte Flaschenhals in der Bereitstellung neuer Features. CI/CD-Pipelines sorgen für Effizienz, Konsistenz und Geschwindigkeit, indem sie den gesamten Prozess vom Code-Commit bis zur Produktionsfreigabe automatisieren.
Warum Automatisierung essenziell ist
- Schnelligkeit: Automatisierte Deployments reduzieren Wartezeiten und ermöglichen häufigere Releases.
- Konsistenz: Manuelle Fehler werden eliminiert, da der Prozess jedes Mal auf die gleiche Weise abläuft.
- Sicherheit: Automatische Tests und Validierungen stellen sicher, dass nur stabile Versionen produktiv gehen.
- Nachvollziehbarkeit: Änderungen sind durch Pipeline-Logs jederzeit zurückverfolgbar.
Beispiel: Deployment-Pipeline mit GitHub Actions
Eine typische CI/CD-Pipeline mit GitHub Actions: Build, Test, Deploy auf Staging, Smoke-Test, dann Produktion. Die Pipeline stoppt automatisch, wenn ein Schritt fehlschlägt.
name: Deploy to Production
on:
push:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: npm test
- run: npm run build
deploy-staging:
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: ./deploy.sh --target staging
- name: Smoke Test Staging
run: |
curl -sf https://staging.example.com/health || exit 1
npm run test:e2e -- --base-url https://staging.example.com
deploy-prod:
needs: deploy-staging
runs-on: ubuntu-latest
environment: production # Erfordert manuelle Freigabe
steps:
- uses: actions/checkout@v4
- run: ./deploy.sh --target production
- name: Smoke Test Production
run: curl -sf https://www.example.com/health || exit 1Entscheidend: Das environment: production erzwingt eine manuelle Freigabe vor dem Prod-Deployment. So bleibt die Kontrolle beim Team, während der Prozess automatisiert abläuft.
Typische Tools für CI/CD
Je nach Tech-Stack und Infrastruktur gibt es zahlreiche Werkzeuge zur Automatisierung von Deployments:
- Build und Test: GitHub Actions, GitLab CI, Jenkins
- Deployment und Orchestrierung: ArgoCD, Flux, Istio (Service Mesh)
- Konfigurationsmanagement: Terraform, Ansible, Pulumi
- Container-Plattformen: Kubernetes, AWS ECS und EKS, Azure AKS
„Tools wechseln. Qualitätsdenken bleibt." Die Tools im Deployment-Stack ändern sich alle paar Jahre. Was bleibt, ist eine durchdachte Strategie für Tests, Rollback und Monitoring.
Infrastructure as Code: Wie es Deployments beschleunigt
IaC ist ein weiterer Schlüssel zur Automatisierung, da es Infrastrukturänderungen als Code definiert und verwaltet. Tools wie Terraform, Pulumi und Helm für Kubernetes ermöglichen es, komplette Umgebungen konsistent und reproduzierbar bereitzustellen, sei es in der Cloud oder On-Premises. Cloud-Strategien dafür zeigen wir in unseren Artikeln zu AWS und Microsoft Azure.
Wie Sie Linting in der CI/CD-Pipeline als blockierendes Quality-Gate verankern, zeigt der Praxis-Guide Linting & Quality-Gate: Code-Qualität in der CI/CD-Pipeline.
Deployment Monitoring und Observability

Ein Deployment endet nicht mit dem Klick auf „Deploy". Erst durch Monitoring entdecken Teams, ob die neue Version stabil läuft. Wer das nicht systematisch macht, deployt im Blindflug und hofft auf User-Bugreports. Drei Beobachtungs-Ebenen prägen reife Setups.
Synthetische Smoke-Tests
Direkt nach jedem Deployment laufen automatisierte Tests gegen kritische User-Flows: Login, Checkout, Suche, Zahlungsabwicklung. Playwright-Tests dauern wenige Minuten und stoppen die Pipeline, wenn ein User-Flow nicht funktioniert. So fallen Konfigurationsfehler auf, bevor echte Nutzer betroffen sind.
Performance- und Last-Monitoring
Neue Versionen können bestehende Last-Profile verändern. Eine Query, die in der alten Version mit 50 ms reagierte, kann in der neuen mit 500 ms zurückkommen. Performance-Tests in der Pipeline (etwa mit QLoad oder JMeter) fangen solche Regressionen vor dem Produktiv-Rollout ab. Eine ausführliche Pipeline-Anbindung zeigt unser Artikel zu Continuous Performance Testing.
APM und Real-User-Monitoring
In Produktion liefern APM-Tools wie Datadog, New Relic oder Dynatrace Echtzeit-Daten zu Fehlerraten, Latenzen und Throughput. Real-User-Monitoring ergänzt das mit Daten echter Sitzungen: Welche Browser, welche Geräte, welche Netzwerkbedingungen treten Probleme auf? Quality Gates auf APM-Daten (z. B. „Fehlerrate darf nicht über 1 Prozent steigen") können den automatischen Rollback auslösen.
Wer einen strukturierten Audit-Pfad zu Test- und Deployment-Monitoring sucht, findet im Service Continuous Testing Beratung einen Einstieg.
Best Practices und Fazit zu Deployments
Erfolgreiche Deployments basieren nicht nur auf der richtigen Strategie, sondern auch auf konsequenten Best Practices. Fehler lassen sich nie vollständig vermeiden, aber mit einer durchdachten Herangehensweise können Risiken minimiert und die Qualität der Softwarebereitstellung maximiert werden.
Ein entscheidender Faktor ist die Automatisierung von Tests. Unit-, Integrations- und End-to-End-Tests sollten fest in die CI/CD-Pipeline integriert sein, um Fehler frühzeitig zu erkennen. Tests auf verschiedenen Ebenen helfen, Regressionen zu vermeiden und sicherzustellen, dass neue Versionen stabil sind, bevor sie in Produktion gehen. Gerade bei datenbanklastigen Anwendungen sind Migrations-Tests essenziell, um Inkompatibilitäten zu verhindern.
Ein weiteres bewährtes Prinzip ist die progressive Einführung neuer Versionen. Statt ein Deployment sofort für alle Nutzer auszurollen, lohnt es sich, stufenweise vorzugehen. Canary Releases oder Feature Toggles ermöglichen es, neue Funktionen zunächst nur einer kleinen Benutzergruppe bereitzustellen, sodass potenzielle Probleme schnell erkannt und behoben werden können.
Ebenso wichtig ist eine klare Deployment- und Rollback-Strategie. Im Idealfall sollte jede neue Version innerhalb weniger Minuten zurückgesetzt werden können, falls kritische Fehler auftreten. Rollbacks über CI/CD-Pipelines oder Helm für Kubernetes bieten hier effektive Möglichkeiten.
Zu guter Letzt spielt die Zusammenarbeit zwischen Dev und Ops eine zentrale Rolle. Ein DevOps-Ansatz, bei dem Entwickler und Betriebsteam gemeinsam Verantwortung für Deployments tragen, verbessert den gesamten Prozess erheblich. Infrastructure-as-Code und GitOps-Prinzipien sorgen für Transparenz und Nachvollziehbarkeit. Eine vertiefte Beratung dazu bietet die DevOps Testing Beratung und die Cloud- und DevOps-Beratung.
Letztlich gilt: Kein Deployment-Prozess ist jemals perfekt. Aber durch konsequente Verbesserungen und den Einsatz bewährter Methoden lassen sich Ausfallzeiten minimieren, Risiken reduzieren und Software schneller und zuverlässiger bereitstellen.
FAQ: Häufig gestellte Fragen zu Deployment-Strategien
Was ist der Unterschied zwischen Blue-Green und Canary Deployment?
Bei Blue-Green laufen zwei komplette Umgebungen parallel und der gesamte Traffic wird auf einmal umgeschaltet. Bei Canary geht die neue Version zuerst an einen kleinen Prozentsatz der Nutzer (z. B. 5 Prozent), bevor schrittweise auf 100 Prozent hochgefahren wird. Blue-Green braucht doppelte Infrastruktur, bietet dafür sofortiges Rollback. Canary braucht weniger Ressourcen, erfordert aber Traffic-Routing (etwa über Istio oder Nginx).
Was ist Zero Downtime Deployment?
Ein Deployment ohne Ausfallzeit für die Nutzer. Rolling Deployments, Blue-Green und Canary erreichen das, indem alte und neue Version kurzzeitig parallel laufen. Voraussetzung: Die Anwendung muss rückwärtskompatibel sein, insbesondere bei Datenbankänderungen. Wenn die neue Version ein anderes Datenbankschema erwartet als die alte, brechen parallele Instanzen.
Wie plane ich eine Rollback-Strategie?
Drei Fragen vor jedem Deployment: (1) Wie lange dauert ein Rollback? Ziel: unter 5 Minuten. (2) Was passiert mit den Daten? Wenn die neue Version Daten in neuem Format geschrieben hat, muss der Rollback das berücksichtigen. (3) Wer entscheidet? Klare Eskalationskette festlegen, wer den Rollback auslöst. Rollbacks regelmäßig üben, nicht erst im Ernstfall.
Welche Deployment-Strategie passt zu meinem Projekt?
Monolith und Wasserfall: Big Bang (oft vertraglich vorgegeben). Monolith und Agile: Blue-Green (einfaches Rollback). Microservices: Canary oder Rolling (pro Service unabhängig). SaaS mit großer Nutzerbasis: Canary und Feature Toggles (kontrollierte Einführung). Die meisten Teams starten mit Rolling Deployments und führen Canary ein, wenn die Nutzerbasis wächst.
Was ist GitOps und wie hängt es mit Deployments zusammen?
GitOps nutzt Git als Single Source of Truth für Infrastruktur und Deployments. Jede Änderung wird per Pull Request eingereicht, reviewed und dann automatisch angewendet. Tools wie ArgoCD und Flux überwachen das Git-Repository und synchronisieren den Cluster-Zustand automatisch. Vorteil: Jedes Deployment ist nachvollziehbar, wiederholbar und per Git-Revert rückgängig zu machen.
Wie teste ich Deployments automatisiert?
Drei Teststufen pro Deployment: (1) Pre-Deployment: Unit- und Integrationstests in der CI-Pipeline. (2) Post-Deployment Staging: End-to-End-Tests mit Playwright gegen die Staging-Umgebung. (3) Post-Deployment Produktion: Smoke-Tests (Health-Check, kritische User-Flows) plus APM-Monitoring für Fehlerraten und Latenz. Wenn ein Smoke-Test fehlschlägt, automatischer Rollback.